Speculative Prefilling
If you know what a user is gonna do next, you can prefill your KV cache with candidate contexts and significantly improve your time-to-first-token.
The Interaction
I was revisiting an interaction idea I had a bit ago- if we have a great model of user context, then we can effectively build an “everywhere” tab to autocomplete. I called this system Tabracadabra 🎉. Here’s the original demo video:
Pretty cool, huh? You can download and try it here.
The Problem
Now what I kinda hid from you here is that this ORIGINAL clip is sped up quite a bit. That spinner spins for quite some time before you see anything. This time where that spinner is going off is known as the time to first token (or TTFT) for short. You might also notice that once the first token appears, the actual decoding speed is not so bad!
What exactly is going on when the spinner is running? This phase is known as the prefill phase. Here, the model processes all input tokens in parallel, computing the KV. Unlike the decode step, we have all the inputs at the very start, so we compute the full attention matrix at the start! Awesome!
In theory, this should be a LOT faster than decoding, right? We can parallelize the prefill phase, but not the decode phase! So what’s going on?
This is because, in the Tabracadabra setting, the context is an order of magnitude larger than what’s generated. For that demo example, I’m retrieving all of my past emails, screenshots of me in similar settings, etc. etc. We end up in a setting where the context can be 20x-30x larger than the text that’s actually generated.
On top of that, the actual decode speed isn’t really a big interaction bottleneck. Users can early-interrupt decoding and work from a partial autocomplete; but we can’t partially remove parts of the context. And the completion animation looks cool!
Speculative Prefilling
Here’s the idea: if we have a user model that can predict what a user will do next, we can use those predictions to retrieve relevant context ahead of time—and prefill the KV cache before the user ever triggers autocomplete. This is the same intuition behind speculative decoding (pre-generate tokens that might get used, and accept or reject them later) except here we’re speculating over the prefill rather than the decode. That’s it! Here’s a comparison video:
The time to first token here is effectively nothing. To get here, we need an aside on user models:
User Models
We define user models as models that are predictive: they tell us what a user will do next. How do we get a good user model? Under the hood, we use ideas from two of my papers (access to a user model, see GUM and NAP). In NAP specifically, we introduce LongNAP, a user model that predicts what a user will do next given their full multimodal interaction history (screenshots, keystrokes, clicks). LongNAP operates in two phases:
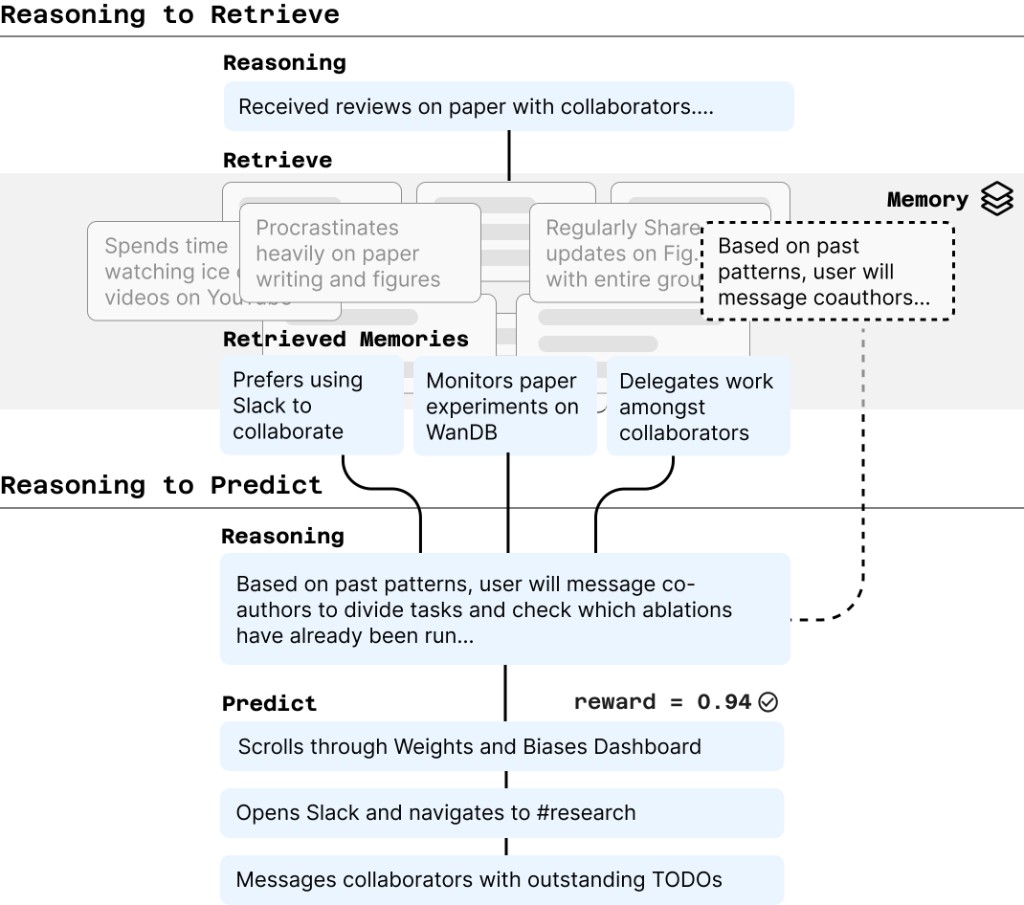
Phase 1: Reasoning to Retrieve. Given the user’s recent context—say, they just opened a set of paper reviews—LongNAP first generates a reasoning trace about what might come next (e.g., “Received reviews on paper with collaborators… user may revise paper after viewing feedback”). This trace then serves as a query to retrieve relevant entries from a memory of the user’s past observations and reasoning. In our example, the retriever might surface past traces like “Procrastinates heavily on paper writing” and “Prefers using Slack to collaborate.”
Phase 2: Reasoning to Predict. With retrieved context in hand, LongNAP revises its initial reasoning and makes a concrete prediction. The retrieved traces about this user’s tendency to delegate allow the model to go from “user may revise paper” to “user will message coauthors to divide tasks, check which experiments have been run”—and predict concrete next actions like opening Slack and scrolling through Weights & Biases.
You can use a prompted scaffold to implement this. In our paper though, the whole pipeline is trained end-to-end via reinforcement learning (GRPO). Since we’re predicting what a user will do, we can just wait and see if they actually do it, scoring predictions against ground truth as a reward (again, more details in the paper).
The Algorithm
With our LongNAP in hand, the actual algorithm here is pretty simple. This “reasoning to retrieve” mechanism is exactly what we need for speculative prefilling. We just run Phase 1 whenever a user’s context switches.
- On context change (e.g. you open an app, switch a tab), run the reasoning to retrieve phase of pθ: generate a reasoning trace about what the user will do next, and use it to retrieve relevant context from the user's history.
- Prefill the KV cache with the retrieved context.
- On autocomplete trigger, decode immediately (TTFT ≈ 0) or add a tiny bit more context.
That’s it. The user model tells us what context to fetch; we just need to fetch it before the user asks. As the user’s context shifts, we re-run Phase 1, keeping the prefilled context relevant.
Systems and User Models
A small aside—I think we can view some of these user models as general purpose human branch predictors. I’ve applied this idea here to LLMs, but you could speculate on any kind of application that might benefit from speculative execution with a user model!
Anyway, if you found this interesting, please consider citing:
NAP (Next Action Prediction):
@misc{shaikh2026learningactionpredictorshumancomputer,
title={Learning Next Action Predictors from Human-Computer Interaction},
author={Omar Shaikh and Valentin Teutschbein and Kanishk Gandhi and Yikun Chi and Nick Haber and Thomas Robinson and Nilam Ram and Byron Reeves and Sherry Yang and Michael S. Bernstein and Diyi Yang},
year={2026},
eprint={2603.05923},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2603.05923},
}GUM (General User Models):
@misc{shaikh2025creatinggeneralusermodels,
title={Creating General User Models from Computer Use},
author={Omar Shaikh and Shardul Sapkota and Shan Rizvi and Eric Horvitz and Joon Sung Park and Diyi Yang and Michael S. Bernstein},
year={2025},
eprint={2505.10831},
archivePrefix={arXiv},
primaryClass={cs.HC},
url={https://arxiv.org/abs/2505.10831},
}